Ingenieur*innen sind zunehmend bestrebt, KI erfolgreich in Projekte und Anwendungen zu integrieren, während sie versuchen, ihre eigene KI-Lernkurve zu meistern. Allerdings werden viele KI-Projekte nach wenig vielversprechenden Ergebnissen wieder verworfen. Woran liegt das? Johanna Pingel, Product Marketing Manager bei MathWorks, erläutert, warum es für Ingenieur*innen wichtig ist, sich auf den gesamten KI-Workflow zu konzentrieren und nicht nur auf die Modellentwicklung:
Ingenieur*innen, die Machine Learning und Deep Learning einsetzen, erwarten oft, dass sie einen großen Teil ihrer Zeit mit der Entwicklung und Feinabstimmung von KI-Modellen verbringen. Die Modellierung ist zwar ein wichtiger Schritt im Workflow, aber das Modell ist nicht alleiniges Ziel. Das Schlüsselelement für den Erfolg bei der praktischen KI-Implementierung ist das frühzeitige Aufdecken von Problemen. Außerdem ist es wichtig zu wissen, auf welche Aspekte des Workflows man Zeit und Ressourcen konzentrieren sollte, um die besten Ergebnisse zu erzielen. Das sind nicht immer die offensichtlichsten Schritte.
Der KI-gesteuerte Workflow
Es lassen sich vier Schritte in einem KI-gesteuerten Workflow differenzieren, wobei jeder Schritt seine eigene Rolle bei der erfolgreichen Implementierung von KI in einem Projekt spielt.
Schritt 1: Datenaufbereitung
Die Datenaufbereitung ist wohl der wichtigste Schritt im KI-Workflow: Ohne robuste und genaue Daten zum Trainieren eines Modells sind Projekte rasch zum Scheitern verurteilt. Wenn Ingenieur*innen das Modell mit „schlechten“ Daten füttern, werden sie keine aufschlussreichen Ergebnisse erhalten – und wahrscheinlich viele Stunden damit verbringen, herauszufinden, warum das Modell nicht funktioniert.
Um ein Modell zu trainieren, sollten Ingenieur*innen mit sauberen, gelabelten Daten beginnen, und zwar mit so vielen wie möglich. Dies kann einer der zeitaufwendigsten Schritte des Workflows sein. Wenn Deep Learning-Modelle nicht wie erwartet funktionieren, konzentrieren sich viele darauf, wie man das Modell verbessern kann – durch das Optimieren von Parametern, die Feinabstimmung des Modells und mehrere Trainingsiterationen. Doch noch viel wichtiger ist die Aufbereitung und das korrekte Labeln der Eingabedaten. Das darf nicht vernachlässigt werden, um sicherzustellen, dass Daten korrekt vom Modell verstanden werden können.
Schritt 2: KI-Modellierung
Sobald die Daten sauber und richtig gelabelt sind, kann zur Modellierungsphase des Workflows übergegangen werden. Hierbei werden die Daten als Input verwendet und das Modell lernt aus diesen Daten. Das Ziel einer erfolgreichen Modellierungsphase ist die Erstellung eines robusten, genauen Modells, das intelligente Entscheidungen auf Basis der Daten treffen kann. Dies ist auch der Punkt, an dem Deep Learning, Machine Learning oder eine Kombination davon in den Arbeitsablauf einfließt. Hier entscheiden die Ingenieur*innen, welche Methoden das präziseste und robusteste Ergebnis hervorbringt.
Die KI-Modellierung ist ein iterativer Schritt innerhalb des gesamten Workflows, und Ingenieur*innen müssen die Änderungen, die sie während dieses Schrittes am Modell vornehmen, nachverfolgen können. Die Nachverfolgung von Änderungen und die Aufzeichnung von Trainingsiterationen mit Tools wie dem Experiment Manager von MathWorks sind entscheidend, da sie helfen die Parameter zu erklären, die zum genauesten Modell führen und reproduzierbare Ergebnisse liefern.
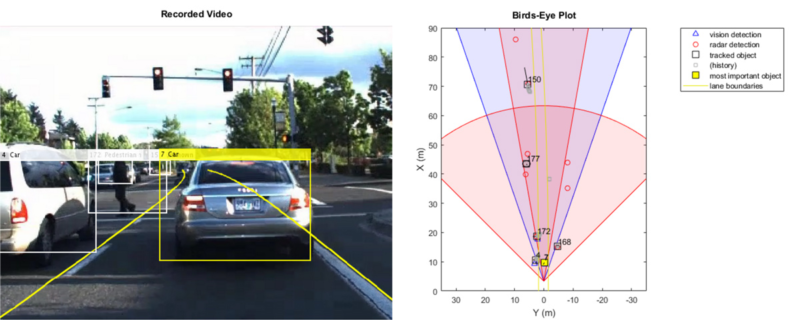
Schritt 3: Simulation und Tests
Ingenieur*innen müssen beachten, dass KI-Elemente meistens nur ein kleiner Teil eines größeren Systems sind. Sie müssen in allen Szenarien im Zusammenspiel mit anderen Teilen des Endprodukts korrekt funktionieren, einschließlich anderer Sensoren und Algorithmen wie Steuerung, Signalverarbeitung und Sensorfusion. Ein Beispiel ist hier ein Szenario für automatisiertes Fahren: Dabei handelt es sich nicht nur um ein System zur Erkennung von Objekten (Fußgänger*innen, Autos, Stoppschilder), sondern dieses System muss mit anderen Systemen zur Lokalisierung, Wegplanung, Steuerung und weiteren integriert werden. Simulationen und Genauigkeitstests sind der Schlüssel, um sicherzustellen, dass das KI-Modell richtig funktioniert und alles gut mit anderen Systemen harmoniert, bevor ein Modell in der realen Welt eingesetzt wird.
Um diesen Grad an Genauigkeit und Robustheit vor dem Einsatz zu erreichen, müssen Ingenieur*innen validieren, dass das Modell in jeder Situation so reagiert, wie es soll. Sie sollten sich auch mit den Fragen befassen, wie exakt das Modell insgesamt ist und ob alle Randfälle abgedeckt sind. Durch den Einsatz von Werkzeugen wie Simulink können Ingenieur*innen überprüfen, ob das Modell für alle erwarteten Anwendungsfälle wie gewünscht funktioniert, und so kosten- und zeitintensive Überarbeitungen vermeiden.
Schritt 4: Einsatz
Ist das Modell reif für die Bereitstellung, folgt als nächster Schritt der Einsatz auf der Zielhardware – mit anderen Worten, die Bereitstellung des Modells in der endgültigen Sprache, in der es implementiert werden soll. Das erfordert in der Regel, dass die Entwicklungsingenieur*innen ein implementierungsbereites Modell nutzen, um es in die vorgesehene Hardwareumgebung einzupassen.
Die vorgesehene Hardwareumgebung kann vom Desktop über die Cloud bis hin zu FPGAs reichen. Mithilfe von flexiblen Werkzeugen wie MATLAB kann der endgültige Code für alle Szenarien generiert werden. Das bietet Ingenieur*innen den Spielraum, ihr Modell in einer Vielzahl von Umgebungen einzusetzen, ohne den ursprünglichen Code neu schreiben zu müssen. Das Deployment eines Modells direkt auf einer GPU kann hier als Beispiel dienen: Die automatische Codegenerierung eliminiert Codierungsfehler, die durch eine manuelle Übersetzung entstehen könnten, und liefert hochoptimierten CUDA-Code, der effizient auf der GPU läuft.
Gemeinsam stärker
Ingenieur*innen müssen keine Datenwissenschaftler*innen oder gar KI-Expert*innen werden, um mit KI erfolgreich zu sein. Mit Werkzeugen für die Datenaufbereitung, Anwendungen zur Integration von KI in ihre Arbeitsabläufe und mit verfügbaren Expert*innen, die Fragen zur KI-Integration beantworten, können sie KI-Modelle auf Erfolgskurs bringen. In jedem dieser Schritte im Workflow haben Ingenieur*innen die Möglichkeit, flexibel ihr eigenes Domänenwissen einzubringen. Dies ist eine wichtige Basis, auf der sie mit den richtigen Ressourcen aufbauen und die sie durch KI ergänzen können.
Über MathWorks
MathWorks ist der führende Entwickler von Software für mathematische Berechnungen. MATLAB, die Programmiersprache für Ingenieurwesen und Wissenschaft, ist eine Programmierumgebung für die Algorithmen-Entwicklung, Analyse und Visualisierung von Daten sowie für numerische Berechnungen. Simulink ist eine Blockdiagramm-basierte Entwicklungsumgebung für die Simulation und das Model-Based Design von technischen Mehrdomänen-Systemen und Embedded Systemen. Ingenieure und Wissenschaftler weltweit setzen diese Produktfamilien ein, um die Forschung sowie Innovationen und Entwicklungen in der Automobilindustrie, der Luft- und Raumfahrt, der Elektronik, dem Finanzwesen, der Biotechnologie und weiteren Industriezweigen zu beschleunigen. MATLAB und Simulink sind zudem an Universitäten und Forschungsinstituten weltweit wichtige Lehr- und Forschungswerkzeuge. MathWorks wurde 1984 gegründet und beschäftigt mehr als 5000 Mitarbeiter in 16 Ländern. Der Hauptsitz des Unternehmens ist Natick, Massachusetts, in den USA. Lokale Niederlassungen in der D-A-CH-Region befinden sich in Aachen, München, Paderborn, Stuttgart und Bern. Weitere Informationen finden Sie unter mathworks.com.